Схема предохранителей Приора: найти и обезвредить
Предохранитель представляет собой плавкий элемент, главной задачей которого является размыкание электрической сети при резком скачке напряжения. Размыкая электросеть, предохранитель защищает устройства и узлы автомобиля от повреждения, а владельца авто – от серьёзных затрат на ремонтные работы.
Автомобили Лада Приора, как и другие представители машин от АвтоВАЗ, имеют свои особенности в расположении наиболее востребованных водителями и механиками зон. Что касается водителей, то тут речь идёт лишь о тех, кто имеет желание разобраться с расположением основных узлов и как минимум самые простые шаги технического обслуживания выполнять самостоятельно. На гаражном сленге это ещё называется «прямыми руками».
Итак, где находятся предохранители на Лада Приора?
Как и в большинстве прочих семейств ВАЗ, на Лада Приора предохранители объединены в монтажные блоки. Это позволило конструкторам сэкономить на проводке и при этом обеспечить безопасность прочим узлам и системам, ведь теперь даже короткое замыкание в худшем случае поражает монтажный блок, который достаточно просто можно заменить, что называется, «коробочкой», хотя сам корпус предохранителей в Приора уже давно составляется из специального стекла.
Схему предохранителей Приора можно легко найти и в инструкции по эксплуатации технического средства, и в интернете. Водители, которые предпочитают иметь эту информацию при себе в дороге, нередко имеют эти картинки в собственных электронных девайсах, чтобы даже от наличия сети никак не зависеть. И, разумеется, имеют при себе набор предохранителей, тем более, что стоимость этих расходных материалов более чем невелика.
Основной монтажный блок с предохранителями располагается по капотом, около аккумуляторной батареи. Предохранители данного блока имеют маркировку F, то есть, рассчитаны на оборудование малой мощности. Кроме того, предохранители основного монтажного блока и проводка к ним имеют разделение по цветам. Так, чтобы найти предохранитель бензонасоса приора где находится, достаточно заглянуть в схему: да, F3, голубого цвета на 15А, ведёт именно на этот предохранитель.
Второй по значимости монтажный блок находится под приборной доской, со стороны водителя.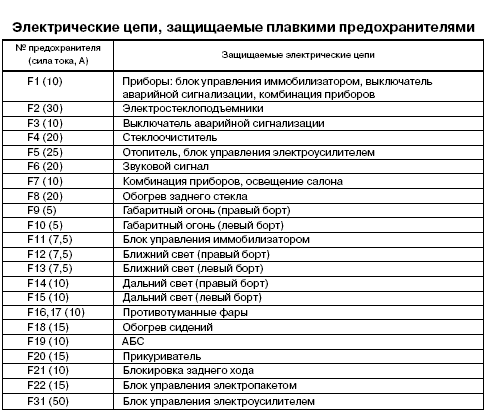
Следует отметить, что для замены любого предохранителя даже специальные инструменты не нужны, достаточно обычных плоскогубцев. Разве что следует предварительно немного потренироваться. Для снятия блока предохранителей достаточно крестовой отвёртки.
С этой статьей так же читают:
блок предохранителей Приоры
просмотров 12 920 Google+Основной блок предохранителей.
На Приоре устанавливается три блока предохранителей, а на моделях с кондиционером четыре. В подкапотном пространстве рядом с аккумуляторной батареей устанавливается основной блок предохранителей Приоры. В нём расположены шесть больших предохранителей номиналом от 30А до 60А. Нумерация предохранителей производится с лева на право.
Защищаемые цепи:
1 Цепи ЭСУД: обмотка главного реле, предохранитель постоянного питания контроллера, предохранитель силовой цепи главного реле (30)
2. Предохранитель цепи питания электровентилятора системы охлаждения двигателя (силовая цепь), дополнительное реле (реле зажигания), обогрев заднего стекла, контроллер электропакета;(60)
3 предохранитель цепи питания электровентилятора системы охлаждения двигателя (управляющая цепь реле), звуковой сигнал, тревожный сигнал, замок зажигания, комбинация приборов, освещение салона, стоп-сигнал, прикуриватель (60)
4,6 Силовая цепь генератора (соединение генератора с аккумуляторной батареей) (60)
5 Цепь питания электроусилителя руля (50)
Блок предохранителей Приоры в салоне автомобиля.

Блок реле и предохранителей под рулевой колонкой.
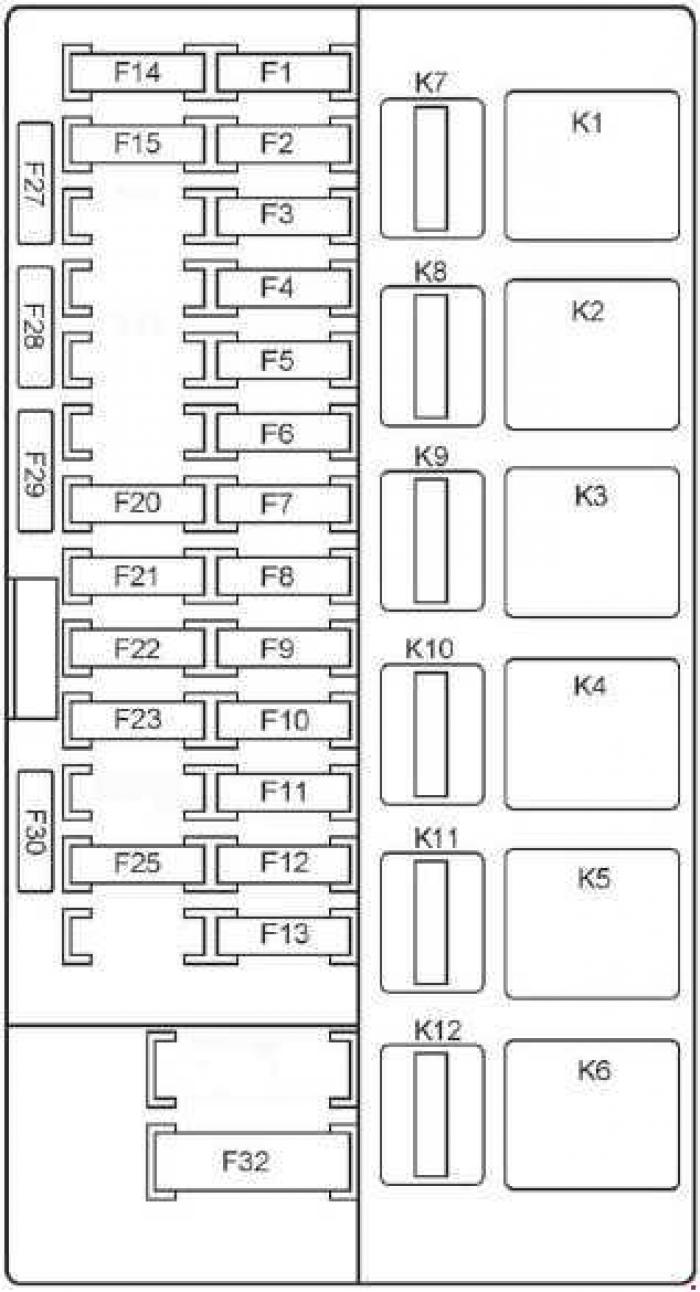
Со стороны водителя под кожухом располагается блок реле и предохранителей (монтажный блок приора). Внешне он очень похож на монтажный блок ВАЗ-2104, ВАЗ-2109 и так далее, но его конструкция и функциональность несколько отличается от них. Главное отличие это отсутствие печатных плат и разъёмов. Провода подключены непосредственно к гнёздам предохранителей и реле, расположенным в пластиковом корпусе.
Подключён блок реле и предохранителей к жгуту проводов панели приборов, проложенному в салоне автомобиля. На данный момент устанавливаются два типа блоков, которые несколько отличаются расположением дополнительных предохранителей.
Ниже приведено описание блок предохранителей Приоры для автомобилей самой полной комплектации.
Блок предохранителей климатической установки.
С левой стороны панели приборов под крышкой находится блок предохранителей Приоры и реле климатической установки. Ниже приведена схема расположения и описание блока предохранителей приора и реле.
Ниже приведена схема расположения и описание блока предохранителей приора и реле.
Предохранители блока управления двигателя.
Под боковой крышкой шахты отопителя со стороны пассажира находятся предохранители и реле электронной системы зажигания и впрыска топлива двигателя. Это расположение свойственно для всех автомобилей серии ВАЗ-2110 и последующих. На Приоре там располагается два реле (1-реле зажигания, 2-реле включения топливного насоса) и четыре предохранителя.
Предохранители системы зажигания:
1-Основной предохранитель (30А) (зщищает все цепи системы зажигания)
2-Предохранитель цепи питания контроллера
3-Предохранитель цепи питания электробензонасоса
4-Предохранитель реле зажигания.
Монтажный блок Приоры — Помощь автолюбителю
Электрика каждого автомобиля нуждается в защите от перегрузок.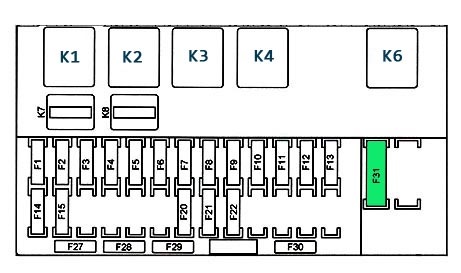 Ведь неисправная проводка губительна для автомобиля. Самый негативный вариант – это возгорание проводки.
Ведь неисправная проводка губительна для автомобиля. Самый негативный вариант – это возгорание проводки.
Как и во всех автомобилях, в автомобиле Приора блок предохранителей призван обезопасить проводку от перегрузок. Он оснащен предохранителями и реле. Реле предназначены для оборудования, требующего для работы ток большой величины. Реле защищают контакты выключателей от перегорания.
Обратим внимание на то, как устроена схема блока предохранителей: Приора комплектуется плавкими предохранителями.
Принцип действия таких предохранителей следующий: при прохождении через предохранитель более высокого тока, чем нужно, плавкая вставка, находящаяся внутри предохранителя перегорает, тем самым размыкая цепь. Такой простой принцип работы спасает электронику автомобиля от поломки.
Помните, в автомобиле отказала какая-либо электроника: будь-то это стеклоподъемники, свет или электрообогреватель сидений – не спешите паниковать и ехать в сервис. Возможно, проблема лишь в том, что предохранитель сделал свою работу и разомкнул цепь.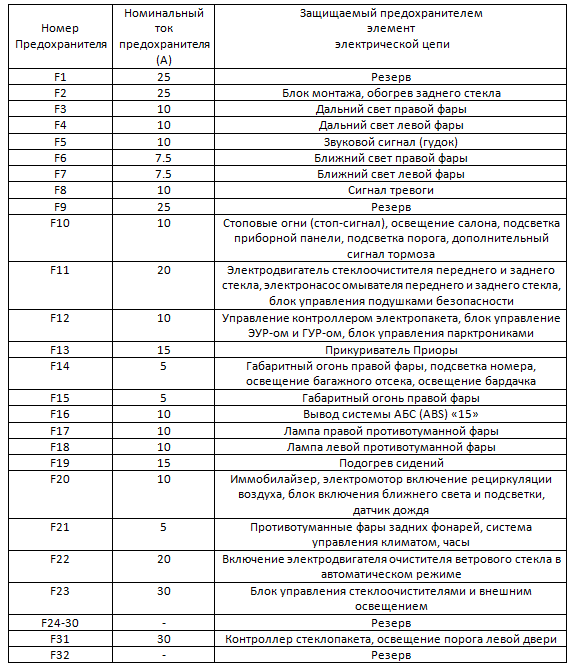
Учитывая, как располагается тот или иной блок предохранителей, ВАЗ 2170 Приора позволяет владельцу самому осуществить замену. Но даже если действительно предохранитель перегорел, не торопитесь его менять. Выясните, по какой причине это произошло. Возможно, в каком-то из участков цепи происходит короткое замыкание. Если его не устранить, то от замены предохранителя не будет толку.
Установленная в автомобиле Лада Приора электросхема: блок предохранителей и реле – позволяет уберечь ваш автомобиль от дорогостоящего ремонта. Важно понимать назначение каждого их элементов, чтобы принимать соответствующие меры.
Если будут иметься знания, как устроен (в совокупности с тем, как устроена у всего автомобиля электрическая схема) блок предохранителей, Приора станет для вас открытой книгой.
В автомобиле Лада Приора, блок предохранителей не один – их несколько. Существует один основной блок и три
5 Приоры | Обновление: набор байесовских заметок
- Байесовские ноты
- 1 Байесовский вывод
- 1,1 Байесовский анализ
- 1,2 Прогнозируемое апостериорное распределение
- I Теория
- 2 Теорема Байеса
- Предварительные условия
- 2.1 Введение в теорему Байеса
- 2,2 Примеры
- 2.2.1 Проблема с такси
- 2,3
 3.1″ data-path=»bayes-theorem.html»> 2.3.1 Вопросы
3.1″ data-path=»bayes-theorem.html»> 2.3.1 Вопросы
- 2,4 Ошибка измерения и редкие события в опросах
 html»> Предисловие
html»> Предисловие- Предварительные требования
- 3,2 Обработка данных
- 3,3 Вероятность возраста по имени и полу
- 3.3.1 Вопросы
 html»> 3.3.2 Ссылки
html»> 3.3.2 Ссылки
- Предпосылки
- 4,1 Введение
- 4,2 Примеры
- 4.2.1 Документы федералиста
- 4.2.2 Добавочные номера
- 4.3 Подробности
- 4.3.1 Генеративные и дискриминационные модели
- 4.3.2 Оценка
- 4.3.3 Прогноз
 4″ data-path=»naive-bayes.html»> 4,4 Ссылки
4″ data-path=»naive-bayes.html»> 4,4 Ссылки- 5.1 Уровни Приоров
- 5.2 Conjugate Priors
- 5.2.1 Binomial-Beta
- 5.2.2 Категориальный-Дирихле
- 5.2.4 Нормальный с известной дисперсией
- 5.2.5 Экспоненциальное семейство
- 5,3 Неправильные приоры
- 5,4 Правило Кромвеля
% PDF-1.3 % 1 0 obj > endobj 2 0 obj > >> endobj 3 0 obj > endobj 4 0 obj > endobj 5 0 obj > endobj 6 0 obj > endobj 7 0 obj > endobj 8 0 объект > endobj 9 0 объект > endobj 10 0 obj > endobj 11 0 объект > endobj 12 0 объект > endobj 13 0 объект > endobj 14 0 объект > endobj 15 0 объект > >> endobj 16 0 объект > endobj 17 0 объект > / XObject> / ProcSet [/ PDF / ImageB / Text] >> / Содержание [20 0 R 18 0 R] >> endobj 18 0 объект > ручей q 609 0 0786 0 0 см / Image1 Do Q конечный поток endobj 19 0 объект > / Декодировать [0 1] >> ручей SC $ n, ItYB =)) 0A} -LX] = { 4? ~ W ݿ zoOR # $ 6% _ # v5l> 8 &> Uh * PM8kCvѴB # Ž «3T = moGK ߠ}% @ $ #
5 (yi
TI-In4: E: 0 $ 8C Ճ! Pv7 䙪 b «R35e? Fz $ RaU: vmq ~ BZ = JeBQ
# N9h (㖂} 7YM5`. ꒥ I $ AXURKKT% WZIhtIkUw փ% .ꪫ
% U ַ_ 멠 ת Ҋ_KR jFR_J QG ~% DZIiPN% R * 8} * JZZTxI-kKU] — / Z ֭? I4_ZuZKWp_tI7 [
T4A $ hN@APm+M45.88Y DGXkM0 «» «» 1L & 0k7] (2 {(VJ + 0sp # p] .zҺk ե D + V @ ZWXTBЅtUUI *] * A (tTUR | 2PqA + i I%
U PWZJBRP PqIHHi * PK5: 1A (yACRHU!} *) 7ð Hqӂ
[. | 4h ACBPqp, ‡ p @ ‘(Z + 5i * FK% P ֹ XkR2
z! P ک m «ah @ + 0Se0RCH
꒥ I $ AXURKKT% WZIhtIkUw փ% .ꪫ
% U ַ_ 멠 ת Ҋ_KR jFR_J QG ~% DZIiPN% R * 8} * JZZTxI-kKU] — / Z ֭? I4_ZuZKWp_tI7 [
T4A $ hN@APm+M45.88Y DGXkM0 «» «» 1L & 0k7] (2 {(VJ + 0sp # p] .zҺk ե D + V @ ZWXTBЅtUUI *] * A (tTUR | 2PqA + i I%
U PWZJBRP PqIHHi * PK5: 1A (yACRHU!} *) 7ð Hqӂ
[. | 4h ACBPqp, ‡ p @ ‘(Z + 5i * FK% P ֹ XkR2
z! P ک m «ah @ + 0Se0RCH
Диаграмма приоритета — решение предшествующих проблем в порядке приоритета
Диаграмма приоритета — это метод получения множества проблем путем мозгового штурма и решения предшествующих проблем в порядке приоритета.
Что такое диаграмма приоритета
Теория диаграммы приоритетности заключается в том, чтобы связать рабочий процесс с ключевыми целями, также известную как Core Success.
Фактор (CSF). Типичные факторы CSF включают цену, качество, характеристики, репутацию,
и т. д., которые дополняют продукт или услугу. Если вы спросите себя: «Что больше всего
важна ценность нашего предприятия в глазах клиентов? «Ответ обычно
ключевой фактор успеха.
Преимущества диаграммы приоритета
Три основных преимущества диаграммы матрицы приоритета:
- Эффективный метод определения основных узких мест, которые, возможно, уже серьезно затрудняет улучшение основных задач.
- Возможность предоставления приоритета, чтобы ресурсы могли быть выделено для продвижения процесса.
- Метод единства, полезный для управленческой команды для поддержки приоритета консенсус всех отделов.
Применение диаграммы предшествования
Цель матрицы приоритета — помочь людям принять решение о проекте. приоритет по весу и решающей значимости.Как только мы узнаем релевантность и варианты с помощью матрицы отношений, диаграммы ассоциаций, древовидной диаграммы и т.д., мы перейдем к стадии принятия решения.
В диаграмме приоритета необходимы два фактора:
(1) Принципы принятия решений,
в зависимости от нашего понимания важных вопросов. например: Экономия, время,
физическая характеристика и форма обслуживания составили основные каталоги
принципы принятия решений.
например: Экономия, время,
физическая характеристика и форма обслуживания составили основные каталоги
принципы принятия решений.
(2) Соответствующий сравнительный метод. Оценка может быть субъективной или задача.
При субъективной оценке, с учетом прошлого опыта и понимания каждого В будущем они все вместе следуют процессу согласования / голосования / базовой очереди. Метод включает метод Delphli — последовательность / план голосования, метод номинальной группы (NGT) и так далее.
При объективной оценке мы указываем соответствующее значение веса и рассчитываем его. значения к относительно предыдущему числу.Процесс аналитической иерархии (AHP) — это широко используемый метод количественной оценки.
Рекомендуемые статьи
Таблица решения проблемы
Примеры ментальных карт
Диаграмма сверху вниз
Программное обеспечение круговой диаграммы
Программное обеспечение Arrows Diagram
EPO — Что такое предшествующий уровень техники?
Уровень техники — любой свидетельство того, что ваше изобретение уже известно.
Предшествующий уровень техники не обязательно должен существовать физически или быть в продаже. Достаточно того, что кто-то где-то когда-нибудь ранее описал, показал или сделал что-то, что содержит использование технология, очень похожая на ваше изобретение.
Доисторическая наскальная живопись может быть предшествующим уровнем техники. Кусок технология, которой много веков, может быть предшествующим уровнем техники. Ранее описанная идея то, что не может работать, может быть предшествующим уровнем техники. Все, что угодно, может быть предшествующим уровнем техники.
Существующий продукт является наиболее очевидной формой известного уровня техники. Это может привести к распространенной ошибке многих изобретателей: просто потому, что они не могут найти продукт, содержащий их изобретение для продажи в любых магазинах, они предполагают что их изобретение должно быть новым.
Реальность совсем иная. Многие изобретения так и не стали продуктом, но могут быть свидетельства
их где-то .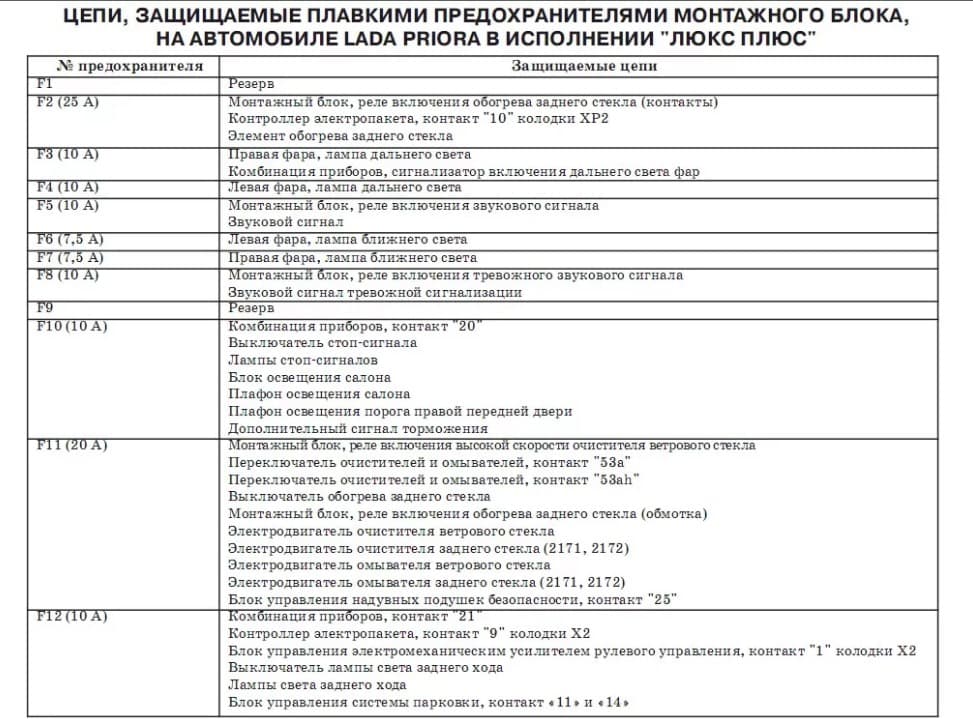 Эти доказательства — в какой бы форме они ни были — будут предварительными.
Изобразительное искусство.
Эти доказательства — в какой бы форме они ни были — будут предварительными.
Изобразительное искусство.
Точной статистики нет, но некоторые эксперты подсчитайте, что для каждого зарегистрированного изобретения, которое в конечном итоге выходит на рынок, десять никогда не будет.Это означает, что если вы хотите узнать, является ли ваше изобретение роман, вы действительно должны искать продукты прошлого и настоящего, но вы также должны ищите гораздо дальше.
Наиболее важным местом для дальнейшего поиска известного уровня техники является всемирная патентная система. Некоторые патентные базы данных, включая Европейский патент Бесплатная база данных офиса Espacenet — содержат 90 миллионов документы, собранные и проиндексированные в течение многих лет патентными ведомствами многих страны.
Благодаря Интернету и международному
системы классификации, используемые для систематизации изобретений по предметам, это довольно просто
для изобретателей проводить собственный патентный поиск. Опишем, как это сделать
позже.
Опишем, как это сделать
позже.
Конкуренция Изобразительное искусство
При поиске известного уровня техники вам также следует искать конкурирующий арт . Это идеи, которые могут не быть совсем как твой но сделать то же самое Работа . Изучение конкурирующего искусства важно по двум причинам:
- Наиболее изобретения — это решение проблемы, и большинство проблем имеют более одного возможное решение. Вам необходимо изучить другие решения, так как некоторые могут предложить больше преимущества, чем у вас.
- если ты попробуйте использовать свою идею в коммерческих целях, альтернативные решения могут оказаться сильными конкуренция. Чтобы успешно доказать, что ваше решение лучше альтернатив, вам нужно знать, какие есть альтернативы!
Диспетчер SDK NVIDIA Универсальный инструмент, который объединяет программное обеспечение разработчика и предоставляет решение по настройке среды разработки для NVIDIA SDK. |
Установка системы NVIDIA DRIVE ™ AGX с помощью NVIDIA SDK Manager Краткое руководствоИспользуйте это краткое руководство для настройки системы DRIVE AGX с помощью NVIDIA SDK Manager. |
NVIDIA DRIVE ™ OS 5.1 Linux SDK Руководство разработчикаРуководство по созданию программных приложений для DRIVE OS для развертывания на аппаратных платформах на базе NVIDIA DRIVE ™ AGX. |
Системы NVIDIA Nsight ™Общесистемный инструмент анализа производительности, предназначенный для визуализации алгоритмов приложения. |
Графика NVIDIA Nsight ™ Автономное приложение для отладки, профилирования и анализа графических приложений. |
NVIDIA® DriveWorks SDK 2.2Исчерпывающая библиотека модулей, инструментов разработчика и справочных приложений, использующих вычислительную мощность платформы NVIDIA DRIVE ™. |
Набор инструментов NVIDIA CUDA®Платформа параллельных вычислений и модель программирования, разработанная NVIDIA для общих вычислений на графических процессорах (GPU). |
TensorRT Высокопроизводительный оптимизатор логических выводов глубокого обучения и среда выполнения, обеспечивающие низкую задержку и высокую пропускную способность логических выводов для приложений глубокого обучения. |
у.е. DNN 7,6Библиотека примитивов для глубоких нейронных сетей с ускорением на GPU. |
NVIDIA DRIVE ™ AVПредоставляет возможности для восприятия, отображения и планирования с использованием DriveWorks SDK. |
NVIDIA DRIVE ™ AR / IX / HubПрограммное обеспечение дополненной реальности для автомобильной кабины и интеллектуальные возможности для помощи водителю. |


Получение 3 парафраз. 3.1 Обзор. 2 предыдущие работы
1 Неконтролируемое получение перефразирования с помощью Relation Discovery Takaaki Hasegawa Cyberspace Laboratories Nippon Telegraph and Telephone Corporation 1-1 Хикариноока, Йокосука, Канагава, Япония. Резюме. событие.Эти выражения называются парафразами. Перефразирование важно в таких приложениях, как IR, QA и IE, и одна из трудностей при исследовании перефразирования — получение необходимых знаний о перефразировании. В этой статье мы описываем неконтролируемый метод обнаружения перефразировок, содержащих две именованные сущности, из большого непомеченного корпуса. Предлагаемый способ состоит из двух этапов. Во-первых, он находит отношения между именованными объектами, используя сходство контекста и кластеризацию. Затем фразы, которые выражают отношение, выбираются из каждого кластера для перефразирования.Наши эксперименты с газетой за один год показывают, что мы можем обнаружить множество перефразирований с высокой точностью и хорошей запоминаемостью. 1 Введение Одна из трудностей обработки естественного языка заключается в том, что существует множество способов выразить одно и то же или событие. Если выражение представляет собой слово или короткую фразу (например, корпорация или компания), это называется синонимом.
Резюме. событие.Эти выражения называются парафразами. Перефразирование важно в таких приложениях, как IR, QA и IE, и одна из трудностей при исследовании перефразирования — получение необходимых знаний о перефразировании. В этой статье мы описываем неконтролируемый метод обнаружения перефразировок, содержащих две именованные сущности, из большого непомеченного корпуса. Предлагаемый способ состоит из двух этапов. Во-первых, он находит отношения между именованными объектами, используя сходство контекста и кластеризацию. Затем фразы, которые выражают отношение, выбираются из каждого кластера для перефразирования.Наши эксперименты с газетой за один год показывают, что мы можем обнаружить множество перефразирований с высокой точностью и хорошей запоминаемостью. 1 Введение Одна из трудностей обработки естественного языка заключается в том, что существует множество способов выразить одно и то же или событие. Если выражение представляет собой слово или короткую фразу (например, корпорация или компания), это называется синонимом. Было проведено множество исследований таких лексических отношений, а также были созданы такие ресурсы, как WordNet. Если выражение длиннее или сложнее (например, A покупает B, а A покупает B), это называется перефразированием, т.е.е. набор фраз, которые выражают одно и то же или событие. В последнее время этой теме уделяется все больше внимания, что очевидно, что Сатоши Секин и Ральф Гришман NewYorkUniversity 715 Broadway, 7th floor, New York, NY 10003, USA, из семинаров Paraphrase Workshops в 2003 и 2004 годах, движимых потребностями различных приложений НЛП. Например, в поиске информации (IR) мы должны сопоставить запрос пользователя с выражениями в требуемых документах, а в ответе на вопрос (QA) мы должны найти ответ на вопрос пользователя, даже если формулировка ответ в документе отличается от вопроса.Кроме того, в извлечении информации (IE), в котором система пытается извлечь элементы некоторых событий (например, дату и название компании события корпоративного слияния), несколько экземпляров событий из разных новостных статей должны быть согласованы, даже если они выражаются по-разному.
Было проведено множество исследований таких лексических отношений, а также были созданы такие ресурсы, как WordNet. Если выражение длиннее или сложнее (например, A покупает B, а A покупает B), это называется перефразированием, т.е.е. набор фраз, которые выражают одно и то же или событие. В последнее время этой теме уделяется все больше внимания, что очевидно, что Сатоши Секин и Ральф Гришман NewYorkUniversity 715 Broadway, 7th floor, New York, NY 10003, USA, из семинаров Paraphrase Workshops в 2003 и 2004 годах, движимых потребностями различных приложений НЛП. Например, в поиске информации (IR) мы должны сопоставить запрос пользователя с выражениями в требуемых документах, а в ответе на вопрос (QA) мы должны найти ответ на вопрос пользователя, даже если формулировка ответ в документе отличается от вопроса.Кроме того, в извлечении информации (IE), в котором система пытается извлечь элементы некоторых событий (например, дату и название компании события корпоративного слияния), несколько экземпляров событий из разных новостных статей должны быть согласованы, даже если они выражаются по-разному. . Мы осознали важность перефразирования; однако главное препятствие — это построение перефразированного знания. Например, мы легко можем представить, что количество перефразирований для A покупает B огромно и что невозможно создать исчерпывающие знания.Кроме того, мы не знаем, сколько видов таких наборов парафраз необходимо, чтобы охватить даже некоторые повседневные вещи или события. До сих пор большинство исследователей IE создавали знания перефразирования (или шаблоны IE) вручную и для конкретных задач. Таким образом, существует ограничение, заключающееся в том, что IE может выполняться только для заранее определенной задачи, например, для корпоративных слияний или смены руководства. Чтобы создать систему IE для нового домена, вам нужно потратить много времени на создание знаний. Так что делать технологию IE открытой, как IR или QA, слишком дорого.В этой статье мы предложим неконтролируемый метод обнаружения перефразирований из большого непомеченного корпуса. Мы фокусируемся на фразах, которые имеют две именованные сущности (NE), так как эти типы фраз очень важны для приложений IE.
. Мы осознали важность перефразирования; однако главное препятствие — это построение перефразированного знания. Например, мы легко можем представить, что количество перефразирований для A покупает B огромно и что невозможно создать исчерпывающие знания.Кроме того, мы не знаем, сколько видов таких наборов парафраз необходимо, чтобы охватить даже некоторые повседневные вещи или события. До сих пор большинство исследователей IE создавали знания перефразирования (или шаблоны IE) вручную и для конкретных задач. Таким образом, существует ограничение, заключающееся в том, что IE может выполняться только для заранее определенной задачи, например, для корпоративных слияний или смены руководства. Чтобы создать систему IE для нового домена, вам нужно потратить много времени на создание знаний. Так что делать технологию IE открытой, как IR или QA, слишком дорого.В этой статье мы предложим неконтролируемый метод обнаружения перефразирований из большого непомеченного корпуса. Мы фокусируемся на фразах, которые имеют две именованные сущности (NE), так как эти типы фраз очень важны для приложений IE. После добавления тегов к большому корпусу с помощью автоматического тега NE, метод пытается автоматически найти наборы перефразирований, не получая исходную фразу или какие-либо подсказки. Предлагаемый АП-
После добавления тегов к большому корпусу с помощью автоматического тега NE, метод пытается автоматически найти наборы перефразирований, не получая исходную фразу или какие-либо подсказки. Предлагаемый АП-
2 proach использует метод обнаружения отношений, описанный в (Hasegawa et al.04). Это неконтролируемый метод поиска общих отношений из большого корпуса. Мы опишем этот метод ниже, поскольку он является неотъемлемой частью нашей процедуры обнаружения перефразирования. Остальная часть этой статьи организована следующим образом. Мы обсуждаем предыдущие работы по обнаружению перефразировок и их ограничения в разделе 2. Мы описываем наш метод в разделе 3. Затем мы сообщаем об экспериментах и оценках в разделе 4 и обсуждаем результат в разделе 5. 2 Предыдущие работы Было предпринято несколько попыток, чтобы обнаруживать перефразирование автоматически из корпусов.Один общий подход использует сопоставимые документы, которые представляют собой наборы документов, содержание которых, как известно, почти одинаково. Другими словами, эти методы требуют сопоставимых корпусов, неявных или явных, таких как разные газетные статьи об одном и том же событии (Шиньяма и Секинэ 03) или разные переводы одной и той же истории (Барзилай 01). В основном они пытаются найти перефразирование в сопоставимых частях документов, используя такие подсказки, как именованные сущности. Однако доступность сопоставимых корпусов ограничена; в частности, в случае подхода Барзилая, наличие нескольких переводов одной и той же истории явно ограничено.Это существенное ограничение этого общего подхода. Другой подход к поиску перефразирований — это поиск фраз, содержащих похожие предметы и объекты в больших корпусах, с использованием взаимной информации о распределении слов (Lin and Pantel 01). Этот подход предназначен для накопления фраз, полезных для задачи контроля качества, путем предоставления пары, состоящей из двух важных фраз из вопроса и ответа. Таким образом, этот подход требует фразы в качестве начального семени, и, таким образом, возможные отношения, которые необходимо извлечь, естественно ограничены.
Другими словами, эти методы требуют сопоставимых корпусов, неявных или явных, таких как разные газетные статьи об одном и том же событии (Шиньяма и Секинэ 03) или разные переводы одной и той же истории (Барзилай 01). В основном они пытаются найти перефразирование в сопоставимых частях документов, используя такие подсказки, как именованные сущности. Однако доступность сопоставимых корпусов ограничена; в частности, в случае подхода Барзилая, наличие нескольких переводов одной и той же истории явно ограничено.Это существенное ограничение этого общего подхода. Другой подход к поиску перефразирований — это поиск фраз, содержащих похожие предметы и объекты в больших корпусах, с использованием взаимной информации о распределении слов (Lin and Pantel 01). Этот подход предназначен для накопления фраз, полезных для задачи контроля качества, путем предоставления пары, состоящей из двух важных фраз из вопроса и ответа. Таким образом, этот подход требует фразы в качестве начального семени, и, таким образом, возможные отношения, которые необходимо извлечь, естественно ограничены. Также была проведена работа с использованием подхода бутстрэппинга (Brin 98; Agichtein и Gravano 00; Ravichandran и Hovy 02). Их основная стратегия для данной пары типов сущностей состоит в том, чтобы начать с некоторых примеров, таких как несколько известных пар название книги и автор; и найти выражения, содержащие эти имена; затем, используя найденные выражения, найдите больше пар автора и названия книги. Это можно повторить несколько раз и собрать список пар и выражений автора и названия книги. Равичандран продемонстрировал, что собранный список повысил точность системы контроля качества.Однако этим методам нужны начальные семена, поэтому взаимосвязь между объектами должна быть известна заранее. Это ограничение препятствует тому, чтобы технология стала открытой. 3 Получение перефразирования 3.1 Обзор Наша цель состоит в том, чтобы обнаружить перефразирование, которое представляет конкретное отношение между двумя названными объектами. Если бы мы могли идентифицировать пары именованных объектов (таких как Cingular и AT&T Wireless), которые имеют определенную связь (например, слияние и поглощение), мы также могли бы найти перефразировки, выражающие связь между этими двумя именами.
Также была проведена работа с использованием подхода бутстрэппинга (Brin 98; Agichtein и Gravano 00; Ravichandran и Hovy 02). Их основная стратегия для данной пары типов сущностей состоит в том, чтобы начать с некоторых примеров, таких как несколько известных пар название книги и автор; и найти выражения, содержащие эти имена; затем, используя найденные выражения, найдите больше пар автора и названия книги. Это можно повторить несколько раз и собрать список пар и выражений автора и названия книги. Равичандран продемонстрировал, что собранный список повысил точность системы контроля качества.Однако этим методам нужны начальные семена, поэтому взаимосвязь между объектами должна быть известна заранее. Это ограничение препятствует тому, чтобы технология стала открытой. 3 Получение перефразирования 3.1 Обзор Наша цель состоит в том, чтобы обнаружить перефразирование, которое представляет конкретное отношение между двумя названными объектами. Если бы мы могли идентифицировать пары именованных объектов (таких как Cingular и AT&T Wireless), которые имеют определенную связь (например, слияние и поглощение), мы также могли бы найти перефразировки, выражающие связь между этими двумя именами. Исходя из этого предположения, мы предлагаем подход к получению перефразирования через обнаружение отношений из больших текстовых документов. Наш подход полностью неконтролируемый, и нам нужен только именованный тег объекта и большие текстовые корпуса. Схема метода выглядит следующим образом: 1. Пометьте именованные сущности в текстовых корпусах 2. Выявите определенные отношения путем кластеризации именованных пар сущностей по их контексту 3. Выберите фразы, которые выражают отношение из тех, что в кластере. На рисунке 1 показан обзор метод. Во-первых, из корпуса газет с тегами NE мы извлекаем выражения, содержащие часто встречающиеся пары именованных сущностей; на рисунке это выражения, содержащие пару КОМПАНИЙ A и B, C и D, а также E и F.Затем мы накапливаем контекстные слова, которые используются между этими объектами, например, предлагается купить, договориться о приобретении для A и B. Если контексты для A и B, а также для E и F похожи, вероятно, что эти пары представляют такое же отношение; на рисунке A и B, E и F связаны отношениями M&A.
Исходя из этого предположения, мы предлагаем подход к получению перефразирования через обнаружение отношений из больших текстовых документов. Наш подход полностью неконтролируемый, и нам нужен только именованный тег объекта и большие текстовые корпуса. Схема метода выглядит следующим образом: 1. Пометьте именованные сущности в текстовых корпусах 2. Выявите определенные отношения путем кластеризации именованных пар сущностей по их контексту 3. Выберите фразы, которые выражают отношение из тех, что в кластере. На рисунке 1 показан обзор метод. Во-первых, из корпуса газет с тегами NE мы извлекаем выражения, содержащие часто встречающиеся пары именованных сущностей; на рисунке это выражения, содержащие пару КОМПАНИЙ A и B, C и D, а также E и F.Затем мы накапливаем контекстные слова, которые используются между этими объектами, например, предлагается купить, договориться о приобретении для A и B. Если контексты для A и B, а также для E и F похожи, вероятно, что эти пары представляют такое же отношение; на рисунке A и B, E и F связаны отношениями M&A. Мы полагаем, что с помощью этого метода мы можем накапливать экземпляры фраз, а также экземпляры отношений, которые важны в тексте.
Мы полагаем, что с помощью этого метода мы можем накапливать экземпляры фраз, а также экземпляры отношений, которые важны в тексте.
3 aaa Корпус с тегами NE (газета) 1) Извлечение выражений между двумя экземплярами NE 2) создание кластеров из пар NE <Компания-A Компания-B> A предлагает купить предлагаемые приобретения BA, заинтересованность BA в BA ведет переговоры о приобретении Б. обсуждает с Б. Одним из них является ограничение дублирования фразы, при котором фраза должна появляться с некоторым минимальным количеством экземпляров пары NE в кластере. Другое ограничение — это ограничение по общему слову, которое заключается в выборе фраз, содержащих частое слово в кластере. Например, если слово «приобретение» часто встречается в кластере, фразы, включающие слово «приобретение», скорее всего, будут фразами, выражающими отношение, в данном случае отношение M&A. 3.2 Маркировка именованных объектов Предлагаемый нами метод полностью неконтролируемый.Нам не нужны сопоставимые корпуса или какие-либо исходные семена, отобранные вручную. Вместо этого мы используем теггер именованного объекта (NE). Текущие автоматические тегеры именованных объектов имеют вполне удовлетворительную производительность. Кроме того, расширен набор типов сетевых элементов. Например, (Sekine et al. 02) предложил 150 типов NE. Расширение типов сетевых элементов приведет к более эффективному обнаружению отношений.
Одним из них является ограничение дублирования фразы, при котором фраза должна появляться с некоторым минимальным количеством экземпляров пары NE в кластере. Другое ограничение — это ограничение по общему слову, которое заключается в выборе фраз, содержащих частое слово в кластере. Например, если слово «приобретение» часто встречается в кластере, фразы, включающие слово «приобретение», скорее всего, будут фразами, выражающими отношение, в данном случае отношение M&A. 3.2 Маркировка именованных объектов Предлагаемый нами метод полностью неконтролируемый.Нам не нужны сопоставимые корпуса или какие-либо исходные семена, отобранные вручную. Вместо этого мы используем теггер именованного объекта (NE). Текущие автоматические тегеры именованных объектов имеют вполне удовлетворительную производительность. Кроме того, расширен набор типов сетевых элементов. Например, (Sekine et al. 02) предложил 150 типов NE. Расширение типов сетевых элементов приведет к более эффективному обнаружению отношений. Например, если тип ОРГАНИЗАЦИЯ разделен на несколько подтипов, таких как КОМПАНИЯ, ВОЕННАЯ, ПРАВИТЕЛЬСТВЕННАЯ и т. Д., Процедура обнаружения может обнаруживать более конкретные отношения, такие как отношения между КОМПАНИЯМИ.Мы используем расширенный тегер NE (ссылка будет предоставлена в заключительной статье). 3.3 Обнаружение отношения Мы определяем совместную встречаемость между парами NE следующим образом: два названных объекта считаются взаимодействующими, если они появляются не более чем с 5 промежуточными словами в одном предложении. Мы собираем промежуточные слова между двумя именованными сущностями для каждого совпадения. Эти слова с корнем можно рассматривать как контекст пары именованных сущностей. Разные порядки появления одних и тех же названных сущностей рассматриваются как
Например, если тип ОРГАНИЗАЦИЯ разделен на несколько подтипов, таких как КОМПАНИЯ, ВОЕННАЯ, ПРАВИТЕЛЬСТВЕННАЯ и т. Д., Процедура обнаружения может обнаруживать более конкретные отношения, такие как отношения между КОМПАНИЯМИ.Мы используем расширенный тегер NE (ссылка будет предоставлена в заключительной статье). 3.3 Обнаружение отношения Мы определяем совместную встречаемость между парами NE следующим образом: два названных объекта считаются взаимодействующими, если они появляются не более чем с 5 промежуточными словами в одном предложении. Мы собираем промежуточные слова между двумя именованными сущностями для каждого совпадения. Эти слова с корнем можно рассматривать как контекст пары именованных сущностей. Разные порядки появления одних и тех же названных сущностей рассматриваются как
4 различных совпадения.Менее частые пары NE исключаются, потому что они могут быть менее надежными для обнаружения отношений. Мы устанавливаем порог частоты совместной встречаемости равным 30. Модель векторного пространства контекстных слов и косинусное подобие векторов используются для вычисления сходства между парами NE. Вектор контекста для каждого экземпляра пары NE состоит из набора слов, образованного из всех промежуточных слов (исключая стоп-слова) двух именованных объектов. Каждое слово вектора контекста взвешивается по tf * idf, произведению частоты термина и обратной частоты документа.Частота термина — это количество вхождений слова в собранные контекстные слова. Частота документов — это количество документов, в которых есть слово. Сходство двух пар именованных сущностей рассчитывается по косинусному сходству двух векторов. Мы сравниваем пары NE одинаковых типов NE, например, пару ЛИЦО-ГПО (географически-политическая единица — регион с правительством). В этой статье мы будем называть пару именованных типов сущностей доменом. Помимо домена PERSON-GPE, мы будем сообщать о нашем эксперименте с доменом COMPANY-COMPANY.
Мы устанавливаем порог частоты совместной встречаемости равным 30. Модель векторного пространства контекстных слов и косинусное подобие векторов используются для вычисления сходства между парами NE. Вектор контекста для каждого экземпляра пары NE состоит из набора слов, образованного из всех промежуточных слов (исключая стоп-слова) двух именованных объектов. Каждое слово вектора контекста взвешивается по tf * idf, произведению частоты термина и обратной частоты документа.Частота термина — это количество вхождений слова в собранные контекстные слова. Частота документов — это количество документов, в которых есть слово. Сходство двух пар именованных сущностей рассчитывается по косинусному сходству двух векторов. Мы сравниваем пары NE одинаковых типов NE, например, пару ЛИЦО-ГПО (географически-политическая единица — регион с правительством). В этой статье мы будем называть пару именованных типов сущностей доменом. Помимо домена PERSON-GPE, мы будем сообщать о нашем эксперименте с доменом COMPANY-COMPANY. 3.4. Кластеризация После того, как мы вычислили сходство между контекстными векторами пар NE, мы создаем кластеры пар NE на основе подобия. Мы применяем иерархическую кластеризацию и использовали полное связывание, чтобы избежать цепного эффекта однозвенной кластеризации, которая могла бы объединить двух не очень похожих членов в один кластер. В методе полной связи расстояние между кластерами берется как расстояние до самых дальних узлов в двух кластерах. Теперь у нас есть набор именованных пар сущностей, которые, вероятно, выражают одно и то же отношение.3.5 Выбор перефразирований. Несмотря на то, что был найден набор пар именованных сущностей в одном и том же отношении, не все фразы, используемые в этих кластерах, выражают это отношение. Чтобы отфильтровать фразы, которые не выражают отношения, мы применили два ограничения: [Ограничение дублирования фразы:] Фраза должна использоваться как минимум двумя парами сетевых элементов в кластере. [Ограничение по общему слову:] Фраза должна включать одно из часто используемых слов в кластере.
3.4. Кластеризация После того, как мы вычислили сходство между контекстными векторами пар NE, мы создаем кластеры пар NE на основе подобия. Мы применяем иерархическую кластеризацию и использовали полное связывание, чтобы избежать цепного эффекта однозвенной кластеризации, которая могла бы объединить двух не очень похожих членов в один кластер. В методе полной связи расстояние между кластерами берется как расстояние до самых дальних узлов в двух кластерах. Теперь у нас есть набор именованных пар сущностей, которые, вероятно, выражают одно и то же отношение.3.5 Выбор перефразирований. Несмотря на то, что был найден набор пар именованных сущностей в одном и том же отношении, не все фразы, используемые в этих кластерах, выражают это отношение. Чтобы отфильтровать фразы, которые не выражают отношения, мы применили два ограничения: [Ограничение дублирования фразы:] Фраза должна использоваться как минимум двумя парами сетевых элементов в кластере. [Ограничение по общему слову:] Фраза должна включать одно из часто используемых слов в кластере. Ограничение дублирования фразы требует, чтобы фраза появилась в нескольких парах NE в одном кластере.Он предназначен для удаления фраз, которые появляются случайно или являются определенными фразами для конкретной пары сетевых элементов. В ограничении общего слова мы полагаемся на идею, что слова, часто встречающиеся в кластере, имеют отношение к отношению кластера, и если фраза содержит одно или несколько таких слов, считается, что фраза выражает отношение. 4 Эксперимент Мы представим отчет о нашем эксперименте в два последовательных этапа. Первым этапом было обнаружение отношений, а вторым этапом было приобретение перефразирования.Мы провели эксперимент с годовой публикацией «Нью-Йорк Таймс» (1995) в качестве нашего корпуса, чтобы проверить метод. 4.1 Обнаружение отношения Сначала обнаруживаются часто встречающиеся пары NE, а пары NE вместе с их промежуточными словами извлекаются и группируются. Чтобы оценить результат, мы проанализировали все извлеченные экземпляры пары NE вручную и определили отношения для двух разных доменов.
Ограничение дублирования фразы требует, чтобы фраза появилась в нескольких парах NE в одном кластере.Он предназначен для удаления фраз, которые появляются случайно или являются определенными фразами для конкретной пары сетевых элементов. В ограничении общего слова мы полагаемся на идею, что слова, часто встречающиеся в кластере, имеют отношение к отношению кластера, и если фраза содержит одно или несколько таких слов, считается, что фраза выражает отношение. 4 Эксперимент Мы представим отчет о нашем эксперименте в два последовательных этапа. Первым этапом было обнаружение отношений, а вторым этапом было приобретение перефразирования.Мы провели эксперимент с годовой публикацией «Нью-Йорк Таймс» (1995) в качестве нашего корпуса, чтобы проверить метод. 4.1 Обнаружение отношения Сначала обнаруживаются часто встречающиеся пары NE, а пары NE вместе с их промежуточными словами извлекаются и группируются. Чтобы оценить результат, мы проанализировали все извлеченные экземпляры пары NE вручную и определили отношения для двух разных доменов.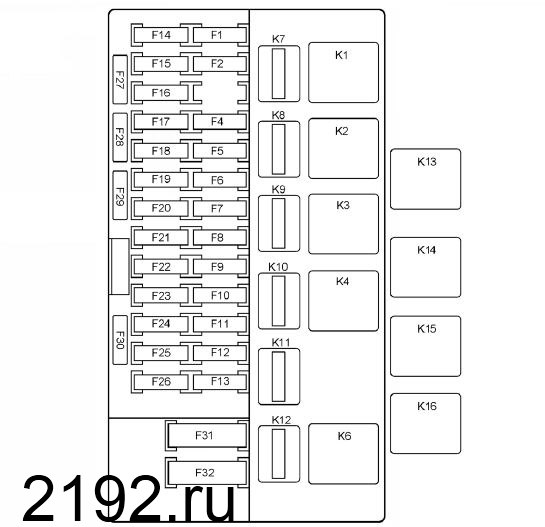 Одним из них был домен PERSON-GPE, в котором было получено 177 различных пар NE и вручную классифицировано на 38 отношений.Другой — домен КОМПАНИЯ-КОМПАНИЯ. Мы получили 65 различных пар NE и вручную классифицировали их на 10 отношений. Мы оценивали автоматически извлеченные кластеры, состоящие из двух и более пар. Для каждого кластера наиболее частое отношение представляет отношение кластера. Например, в кластере, если имеется семь пар NE отношения A и три пары NE отношения B, кластер помечен как A. Когда отношение экземпляра пары NE такое же, как метка кластера, оно считается правильным; количество правильных пар, N правильных, определяется как общее количество правильных пар во всех кластерах.Другие пары NE в кластере считаются неправильными; неверное количество пар, N неверных, также определяется как общее количество неверных пар во всех кластерах. Мы оцениваем кластеры на основе Recall, Precision
Одним из них был домен PERSON-GPE, в котором было получено 177 различных пар NE и вручную классифицировано на 38 отношений.Другой — домен КОМПАНИЯ-КОМПАНИЯ. Мы получили 65 различных пар NE и вручную классифицировали их на 10 отношений. Мы оценивали автоматически извлеченные кластеры, состоящие из двух и более пар. Для каждого кластера наиболее частое отношение представляет отношение кластера. Например, в кластере, если имеется семь пар NE отношения A и три пары NE отношения B, кластер помечен как A. Когда отношение экземпляра пары NE такое же, как метка кластера, оно считается правильным; количество правильных пар, N правильных, определяется как общее количество правильных пар во всех кластерах.Другие пары NE в кластере считаются неправильными; неверное количество пар, N неверных, также определяется как общее количество неверных пар во всех кластерах. Мы оцениваем кластеры на основе Recall, Precision
5 и F-мера. Определения этих мер следующие. [Напомним (R)] Сколько правильных пар обнаружено из всех пар ключей? Количество пар ключей, N ключ, определяется как общее количество пар, вручную классифицированных в кластеры из двух или более пар.Вызов = N правильных / N ключей [Точность (P)] Сколько правильных пар обнаруживается среди пар, сгруппированных автоматически? Точность = N правильных / (N правильных + N неправильных) [F-мера (F)] F-мера определяется как комбинация отзыва и точности согласно следующей формуле: F-мера = 2 * Напоминание * Точность / (Вызов + Prec) Эти значения меняются в зависимости от порога косинусного сходства. Мы зафиксировали порог косинуса на одном значении чуть выше 0 для обоих доменов, что дает почти максимальные значения F для обоих доменов.Этот параметр не требует оптимизации параметров, и мы считаем, что он работает и для других доменов, поскольку это означает, что все члены кластера должны иметь хотя бы одно общее слово с другими членами того же кластера. У нас получилось 34 кластера в домене PER-GPE и 15 кластеров в домене COM-COM.
Определения этих мер следующие. [Напомним (R)] Сколько правильных пар обнаружено из всех пар ключей? Количество пар ключей, N ключ, определяется как общее количество пар, вручную классифицированных в кластеры из двух или более пар.Вызов = N правильных / N ключей [Точность (P)] Сколько правильных пар обнаруживается среди пар, сгруппированных автоматически? Точность = N правильных / (N правильных + N неправильных) [F-мера (F)] F-мера определяется как комбинация отзыва и точности согласно следующей формуле: F-мера = 2 * Напоминание * Точность / (Вызов + Prec) Эти значения меняются в зависимости от порога косинусного сходства. Мы зафиксировали порог косинуса на одном значении чуть выше 0 для обоих доменов, что дает почти максимальные значения F для обоих доменов.Этот параметр не требует оптимизации параметров, и мы считаем, что он работает и для других доменов, поскольку это означает, что все члены кластера должны иметь хотя бы одно общее слово с другими членами того же кластера. У нас получилось 34 кластера в домене PER-GPE и 15 кластеров в домене COM-COM. Таблица 1 показывает результат в обоих доменах. Мы достигли 80 F-мер в домене PER-GPE и 75 в домене COM-COM. Домен Prec. Напомним, F PER-GPE COM-COM Таблица 1. Результат кластеризации отношений 4.2 Получение перефразирования На втором этапе мы собираемся получить пересказы из кластеров одного и того же отношения. Хотя мы получили некоторые значимые отношения в меньших кластерах, мы сосредоточимся на более крупных кластерах, состоящих из более чем 4 членов. Мы обнаружили, что все большие кластеры имеют значимые главные отношения и что общие слова в этих кластерах точно представляют отношения. Большие кластеры представляют отношения между президентом, сенатором, премьер-министром, губернатором, секретарем, республиканцем и тренером в домене PER-GPE, а также отношения слияния и поглощения, материнские компании и альянсы в домене COM-COM.Мы составили эталонный набор перефразирований, просмотрев фразы в каждом кластере для обоих доменов. Мы исключили из оценки одночастотные фразы и фразы, состоящие только из символов и стоп-слов.
Таблица 1 показывает результат в обоих доменах. Мы достигли 80 F-мер в домене PER-GPE и 75 в домене COM-COM. Домен Prec. Напомним, F PER-GPE COM-COM Таблица 1. Результат кластеризации отношений 4.2 Получение перефразирования На втором этапе мы собираемся получить пересказы из кластеров одного и того же отношения. Хотя мы получили некоторые значимые отношения в меньших кластерах, мы сосредоточимся на более крупных кластерах, состоящих из более чем 4 членов. Мы обнаружили, что все большие кластеры имеют значимые главные отношения и что общие слова в этих кластерах точно представляют отношения. Большие кластеры представляют отношения между президентом, сенатором, премьер-министром, губернатором, секретарем, республиканцем и тренером в домене PER-GPE, а также отношения слияния и поглощения, материнские компании и альянсы в домене COM-COM.Мы составили эталонный набор перефразирований, просмотрев фразы в каждом кластере для обоих доменов. Мы исключили из оценки одночастотные фразы и фразы, состоящие только из символов и стоп-слов. Что касается основного отношения, каждая фраза относится к одному из следующих 4 классов. В таблице 2 показано распределение фраз. [Класс 1:] Фразы, которые представляют главное отношение (т. Е. Строгие пересказы) [Класс 2:] Фразы, которые почти представляют главное отношение, но включают дополнительные слова (т.е. более ограничительные отношения) [Класс 3:] Фразы, которые предлагают более широкий смысл, чем просто основное отношение (т. е. более общие отношения) [Класс 4:] Фразы, которые не могут рассматриваться как представляющие главное отношение (т. е. другие) Фраза класс итого PER-GPE COM-COM Таблица 2. Справочные данные классов фраз PG C + C Дублирование базовой фразы Общее слово Phrase + Common RPFRPFRPFRPF Таблица 3. Результат оценки для обнаружения перефразирования
Что касается основного отношения, каждая фраза относится к одному из следующих 4 классов. В таблице 2 показано распределение фраз. [Класс 1:] Фразы, которые представляют главное отношение (т. Е. Строгие пересказы) [Класс 2:] Фразы, которые почти представляют главное отношение, но включают дополнительные слова (т.е. более ограничительные отношения) [Класс 3:] Фразы, которые предлагают более широкий смысл, чем просто основное отношение (т. е. более общие отношения) [Класс 4:] Фразы, которые не могут рассматриваться как представляющие главное отношение (т. е. другие) Фраза класс итого PER-GPE COM-COM Таблица 2. Справочные данные классов фраз PG C + C Дублирование базовой фразы Общее слово Phrase + Common RPFRPFRPFRPF Таблица 3. Результат оценки для обнаружения перефразирования
6 Затем мы оценили результат эксперимента по перефразированию для домена PER-GPE и домена COM-COM.Существуют три критерия: 1) установка ключевых фраз, относящихся к классу 1 (строгое перефразирование), 2) к классу 1 плюс класс 2 и 3) к классу 1, классу 2 плюс класс 3 (свободные пересказы). Свободные пересказы могут быть полезны в приложении IE. Несмотря на то, что фразы в целом не являются взаимозаменяемыми, эти фразы можно использовать для извлечения информации, если задача является конкретной. Метрика оценки — это обычные показатели отзыва, точности и F. В таблице 3 показаны результаты оценки с использованием различных ограничений (т.е.е. без ограничения, ограничение на дублирование фразы, ограничение общего слова и комбинированные ограничения). В комбинированных ограничениях сохраняются фразы, удовлетворяющие любому ограничению, а не обоим ограничениям (т.е. дизъюнкция, а не соединение). В ограничении общего слова мы выбираем фразы, для которых сумма относительных частот для каждого общего слова была выше 0,4. Воспоминание рассчитывается относительно случая отсутствия ограничений (базовый уровень), поскольку мы сравниваем наборы фраз среди фраз в базовом плане, поэтому отзыв составляет 100% для базового эксперимента.Однако точность базовых показателей невысока, поскольку справочные данные включают много не относящихся к делу фраз.
Свободные пересказы могут быть полезны в приложении IE. Несмотря на то, что фразы в целом не являются взаимозаменяемыми, эти фразы можно использовать для извлечения информации, если задача является конкретной. Метрика оценки — это обычные показатели отзыва, точности и F. В таблице 3 показаны результаты оценки с использованием различных ограничений (т.е.е. без ограничения, ограничение на дублирование фразы, ограничение общего слова и комбинированные ограничения). В комбинированных ограничениях сохраняются фразы, удовлетворяющие любому ограничению, а не обоим ограничениям (т.е. дизъюнкция, а не соединение). В ограничении общего слова мы выбираем фразы, для которых сумма относительных частот для каждого общего слова была выше 0,4. Воспоминание рассчитывается относительно случая отсутствия ограничений (базовый уровень), поскольку мы сравниваем наборы фраз среди фраз в базовом плане, поэтому отзыв составляет 100% для базового эксперимента.Однако точность базовых показателей невысока, поскольку справочные данные включают много не относящихся к делу фраз. Цель двух ограничений — повысить точность при сохранении высокого уровня отзыва. Наилучший результат получается с ограничением общего слова в домене PER-GPE и с комбинированными ограничениями в домене COM-COM. В общем, ограничение общего слова помогает повысить точность по сравнению с ограничениями дублированной фразы. Это означает, что перефразирование в кластерах не так часто используется разными экземплярами пары NE, даже если перефразирование имеет некоторые общие слова.В домене COM-COM есть множество фраз по сравнению с доменом PER-GPE. В области PERGPE существует довольно небольшое количество типичных фраз для отношения (например, A — президент B). Мы считаем, что домен PER-GPE содержит больше статических отношений по сравнению с доменом COM-COM, который содержит больше отношений событий. Это предположение также подтверждается тем результатом, что ограничение дублирования фразы работает лучше в домене PER-GPE. В таблице 4 показаны некоторые примеры успешно приобретенных перефразировок для отношений M&A и Parent в домене COM-COM с использованием комбинированных ограничений.
Цель двух ограничений — повысить точность при сохранении высокого уровня отзыва. Наилучший результат получается с ограничением общего слова в домене PER-GPE и с комбинированными ограничениями в домене COM-COM. В общем, ограничение общего слова помогает повысить точность по сравнению с ограничениями дублированной фразы. Это означает, что перефразирование в кластерах не так часто используется разными экземплярами пары NE, даже если перефразирование имеет некоторые общие слова.В домене COM-COM есть множество фраз по сравнению с доменом PER-GPE. В области PERGPE существует довольно небольшое количество типичных фраз для отношения (например, A — президент B). Мы считаем, что домен PER-GPE содержит больше статических отношений по сравнению с доменом COM-COM, который содержит больше отношений событий. Это предположение также подтверждается тем результатом, что ограничение дублирования фразы работает лучше в домене PER-GPE. В таблице 4 показаны некоторые примеры успешно приобретенных перефразировок для отношений M&A и Parent в домене COM-COM с использованием комбинированных ограничений. Эти фразы являются перефразированием и могут быть полезны для таких приложений, как поиск информации, ответы на вопросы или извлечение информации. Президент A, президент BB новый президент AB новоизбранный президент, AA становится президентом BB при президенте A M&A Купленный BA согласился купить BA, который покупает предлагаемое приобретение BA приобретение BA компанией BA ‘ Соглашение о покупке BA, сделанное BA, предложение о поглощении BA слияния BA с BA привело к покупке BB, которая была приобретена AB и стала дочерней компанией AB, согласившейся на покупку A Материнская компания A, подразделение BA, принадлежащая материнской компании BA, BB, материнской компании AB, является холдинговой компанией AB, компании, владеющей A Таблица 4.Примеры обнаруженных парафраз 5 Обсуждение В этом разделе мы обсудим несколько вопросов, касающихся предлагаемого метода. Анализ ошибок Мы анализируем ошибки, которые снижают точность, проблема в первую очередь в области PER-GPE (ложные тревоги). Этот анализ был проведен для данных с использованием комбинированных ограничений.
Эти фразы являются перефразированием и могут быть полезны для таких приложений, как поиск информации, ответы на вопросы или извлечение информации. Президент A, президент BB новый президент AB новоизбранный президент, AA становится президентом BB при президенте A M&A Купленный BA согласился купить BA, который покупает предлагаемое приобретение BA приобретение BA компанией BA ‘ Соглашение о покупке BA, сделанное BA, предложение о поглощении BA слияния BA с BA привело к покупке BB, которая была приобретена AB и стала дочерней компанией AB, согласившейся на покупку A Материнская компания A, подразделение BA, принадлежащая материнской компании BA, BB, материнской компании AB, является холдинговой компанией AB, компании, владеющей A Таблица 4.Примеры обнаруженных парафраз 5 Обсуждение В этом разделе мы обсудим несколько вопросов, касающихся предлагаемого метода. Анализ ошибок Мы анализируем ошибки, которые снижают точность, проблема в первую очередь в области PER-GPE (ложные тревоги). Этот анализ был проведен для данных с использованием комбинированных ограничений. Мы разделили ошибки на следующие четыре типа. Распределение ошибок показано в таблице 5.
Мы разделили ошибки на следующие четыре типа. Распределение ошибок показано в таблице 5.
7 [Ошибка 1:] Фраза содержит две разные фразы [Ошибка 2:] Ошибка обнаружения отношения [Ошибка 3:] Отношения зависят от контекста [Ошибка 4:] Другие ошибки Ошибка P-G C-C Таблица 5.Распространение ошибок Самый серьезный тип ошибки (Ошибка 1) включает фразы, которые на самом деле содержат разные фразы. Пример такой фразы — посещение Франции (GPE), когда президент Ширак (PERSON) приглашает мировых лидеров. Поскольку Франс и Ширак часто встречаются одновременно с парами NE и фразами (на самом деле, последовательностью слов) GPE, когда президент PERSON удовлетворяет общему ограничению по словам, это было принято в качестве кандидата на перефразирование. Подобные ошибки снижают точность, но мы считаем, что если мы сможем использовать синтаксический анализатор для нахождения границ фраз, эту ошибку можно будет устранить. Ошибка 2 связана с таким примером, как вице-президент США (GPE) Эл Гор (PERSON). Поскольку контекст содержит слово «президент», пара NE рассматривается как отношение президента. Эту проблему следует решить, используя в качестве ключевого слова частые многословные термины, но это остается одной из наших задач в будущем. Примером ошибки 3 является фраза Томми Томпсон (ЧЕЛОВЕК), республиканец из Висконсина (GPE). На самом деле мистер Томми Томпсон не сенатор и не представитель, а губернатор. Когда предложение появляется в контексте разного взгляда разных губернаторов (т.е. из контекста очевидно, что он губернатор), губернатор прямо не упоминается. Так что фраза может быть перефразированием отношения губернатора в таком контексте, но не всегда. У нас нет хорошей идеи для решения этой ошибки. Ограничения и дальнейшее развитие Наш метод имеет некоторые ограничения. Мы устанавливаем несколько частотных порогов, поэтому мы не можем найти менее частые отношения между парами NE и не можем найти перефразирования для таких отношений.
Ошибка 2 связана с таким примером, как вице-президент США (GPE) Эл Гор (PERSON). Поскольку контекст содержит слово «президент», пара NE рассматривается как отношение президента. Эту проблему следует решить, используя в качестве ключевого слова частые многословные термины, но это остается одной из наших задач в будущем. Примером ошибки 3 является фраза Томми Томпсон (ЧЕЛОВЕК), республиканец из Висконсина (GPE). На самом деле мистер Томми Томпсон не сенатор и не представитель, а губернатор. Когда предложение появляется в контексте разного взгляда разных губернаторов (т.е. из контекста очевидно, что он губернатор), губернатор прямо не упоминается. Так что фраза может быть перефразированием отношения губернатора в таком контексте, но не всегда. У нас нет хорошей идеи для решения этой ошибки. Ограничения и дальнейшее развитие Наш метод имеет некоторые ограничения. Мы устанавливаем несколько частотных порогов, поэтому мы не можем найти менее частые отношения между парами NE и не можем найти перефразирования для таких отношений. Однако мы думаем, что, возможно, мы могли бы снять ограничение двумя способами.Один из подходов — увеличить объем текста. Для этого эксперимента мы использовали только однолетний корпус, но корпусов гораздо больше, например газетный корпус старше 10 лет или гораздо больший корпус веб-текстов. Если мы сможем использовать такие корпуса, можно надеяться, что проблема разреженности будет уменьшена. Другой подход — объединить методы бутстрэппинга (Brin 98; Agichtein и Gravano 00) с нашей стадией обнаружения отношений. Сначала мы находим надежные пересказы, используя частые примеры, затем, используя полученные знания, будут найдены менее частые примеры.Неконтролируемые методы Предлагаемый метод является полностью неконтролируемым методом. Оглядываясь назад на последнее десятилетие, можно заметить, что во многих областях НЛП были достигнуты большие успехи с использованием машинного обучения с учителем. К ним относятся тегеры POS на основе корпуса, тегеры NE и синтаксические анализаторы на основе дерева.
Однако мы думаем, что, возможно, мы могли бы снять ограничение двумя способами.Один из подходов — увеличить объем текста. Для этого эксперимента мы использовали только однолетний корпус, но корпусов гораздо больше, например газетный корпус старше 10 лет или гораздо больший корпус веб-текстов. Если мы сможем использовать такие корпуса, можно надеяться, что проблема разреженности будет уменьшена. Другой подход — объединить методы бутстрэппинга (Brin 98; Agichtein и Gravano 00) с нашей стадией обнаружения отношений. Сначала мы находим надежные пересказы, используя частые примеры, затем, используя полученные знания, будут найдены менее частые примеры.Неконтролируемые методы Предлагаемый метод является полностью неконтролируемым методом. Оглядываясь назад на последнее десятилетие, можно заметить, что во многих областях НЛП были достигнуты большие успехи с использованием машинного обучения с учителем. К ним относятся тегеры POS на основе корпуса, тегеры NE и синтаксические анализаторы на основе дерева. Мы считаем, что это было возможно, потому что эти задачи можно разложить на простые задачи категоризации, а объем необходимого учебного текста достаточно мал, чтобы его можно было подготовить за разумное время и усилия. Однако большинство серьезных приложений НЛП требуют более высокого уровня знаний, в частности семантических знаний.Мы считаем, что эту проблему нельзя решить с помощью небольшой задачи категоризации. Итак, в последнее время мы наблюдаем повышенное внимание к обнаружению семантических знаний из непомеченных корпусов, например (Hearst 92; Riloff 98; Sudo et al. 03). Работа в этой статье преследует ту же цель — найти полезные семантические знания из немаркированных корпусов с помощью неконтролируемых методов. Поскольку нам повезло иметь возможность использовать огромные корпуса, что было невозможно 10 лет назад, мы считаем, что это будет плодотворным направлением для инвестирования наших усилий в развитие технологий НЛП.6 Заключение В этой статье мы предложили неконтролируемый метод обнаружения перефразирований через обнаружение отношений.
Мы считаем, что это было возможно, потому что эти задачи можно разложить на простые задачи категоризации, а объем необходимого учебного текста достаточно мал, чтобы его можно было подготовить за разумное время и усилия. Однако большинство серьезных приложений НЛП требуют более высокого уровня знаний, в частности семантических знаний.Мы считаем, что эту проблему нельзя решить с помощью небольшой задачи категоризации. Итак, в последнее время мы наблюдаем повышенное внимание к обнаружению семантических знаний из непомеченных корпусов, например (Hearst 92; Riloff 98; Sudo et al. 03). Работа в этой статье преследует ту же цель — найти полезные семантические знания из немаркированных корпусов с помощью неконтролируемых методов. Поскольку нам повезло иметь возможность использовать огромные корпуса, что было невозможно 10 лет назад, мы считаем, что это будет плодотворным направлением для инвестирования наших усилий в развитие технологий НЛП.6 Заключение В этой статье мы предложили неконтролируемый метод обнаружения перефразирований через обнаружение отношений. Основная идея заключалась в том, чтобы, во-первых, обнаружить связь между названными объектами путем кластеризации их контекстов; а затем выбор фраз, выражающих основную связь кластера, с использованием ограничения дублирования фраз и ограничения общего слова. Наши эксперименты с газетой за год показывают, что мы смогли обнаружить множество перефразий с высокой точностью и
Основная идея заключалась в том, чтобы, во-первых, обнаружить связь между названными объектами путем кластеризации их контекстов; а затем выбор фраз, выражающих основную связь кластера, с использованием ограничения дублирования фраз и ограничения общего слова. Наши эксперименты с газетой за год показывают, что мы смогли обнаружить множество перефразий с высокой точностью и
8 высокий уровень отзыва через ограничение выбора фразы, а также процесс обнаружения отношения.на 41-м ежегодном собрании Ассоциации компьютерной лингвистики (ACL03) Ссылки Агихтейн, Юджин и Гравано, Луис Сноуболл: извлечение ответов из больших текстовых сочетаний. В Proc. 5-й Международной конференции ACM по цифровым библиотекам (ACM DL00), с. Барзилай, Регина и МакКаун, Кэтлин Извлечение перефразирований из параллельного корпуса. В Proc. 39-го ежегодного собрания Ассоциации компьютерной лингвистики (ACL-EACL01), Брин, Сергей Извлечение шаблонов и связей из всемирной паутины.В Proc. семинара WebDB на 6-й Международной конференции по расширению технологии баз данных (WebDB98), pp Hasegawa, Takaaki, Sekine, Satoshi and Grishman, Ralph, открывающий отношения между именованными сущностями из крупных корпораций, In the Proc. 42-го ежегодного собрания Ассоциации компьютерной лингвистики (ACL04), стр. Херст, Марти А. Автоматическое получение гипонимов из больших корпусов текстов. В материалах Четырнадцатой Международной конференции по компьютерной лингвистике (COLING92). Лин, Деканг и Пантел, Патрик Дирт: открытие правил вывода из текста.В Proc. 7-й Международной конференции ACM SIGKDD по открытию знаний и интеллектуальному анализу данных (KDD01), pp Ravichandran, Deepak and Hovy, Eduard Learning Surface Text Patterns для системы ответов на вопросы. В Proc. ежегодного собрания Ассоциации компьютерной лингвистики (ACL02) Riloff E Автоматическое создание шаблонов извлечения из текста без тегов. В материалах 13-й Национальной конференции по искусственному интеллекту (AAAI96), Секин, Сатоши, Судо, Киёси и Нобата Чикаси Расширенная иерархия именованных сущностей.В Proc. Третьей Международной конференции по языковым ресурсам и оценке (LREC02), стр. Шиньяма, Юсуке и Секинэ, Сатоши Парафраз, приобретенный для извлечения информации. В Proc. Второго международного семинара по перефразированию (IWP03) Судо Киёси, Секин, Сатоши и Гришман, Ральф Улучшенная модель представления паттернов извлечения для автоматического получения паттернов IE. В Proc.
.